介绍 · Introduction
Tapestry - 基于 Agent Skill Bundle 的轻量级书签知识库
A multi-source content capture, knowledge synthesis, and display skill bundle built for Agent — turning URLs into persistent, synthesizable, and publishable knowledge assets
简单命令,快速安装 Simple commands for a quick installation.
$npx skills add https://github.com/natsufox/tapestry --skill tapestry
$
claude plugin marketplace add https://github.com/NatsuFox/Tapestry
$claude plugin install tapestry@tapestry-skills
概览 · Overview
Tapestry 把 URL 抓取、规范化、知识库综合与展示串成一条可复用的技能管线
One pipeline from raw URL to a publishable knowledge base — capture, normalize, synthesize, display.
Match
来源匹配
按 URL 特征与平台规则路由到专用 crawler,保留来源语义
终端操作 · Terminal Operations
Tapestry 是真实可执行、可观察、可复现的终端工作流
A live recording of Tapestry executing source ingestion end-to-end — real input, real output.
真实操作
录屏来自一次真实运行
Tapestry 的 skill 工作流从命令入口直接落地执行,录屏完整记录了这一过程
流程入口
从单个链接进入整条管线
读取 ingest 规则、选择 crawler、执行采集,并自动进入后续知识处理流程
展示价值
可执行性就是最好的产品证明
访问者看到的是一套从来源到知识资产完整跑通的 AI 原生工作流
知识库 · Knowledge Base
Tapestry 把来源内容转化为的知识库形式的长期资产,并加以展示
Structured, readable, and ready to publish — the knowledge base is what Tapestry's pipeline produces.
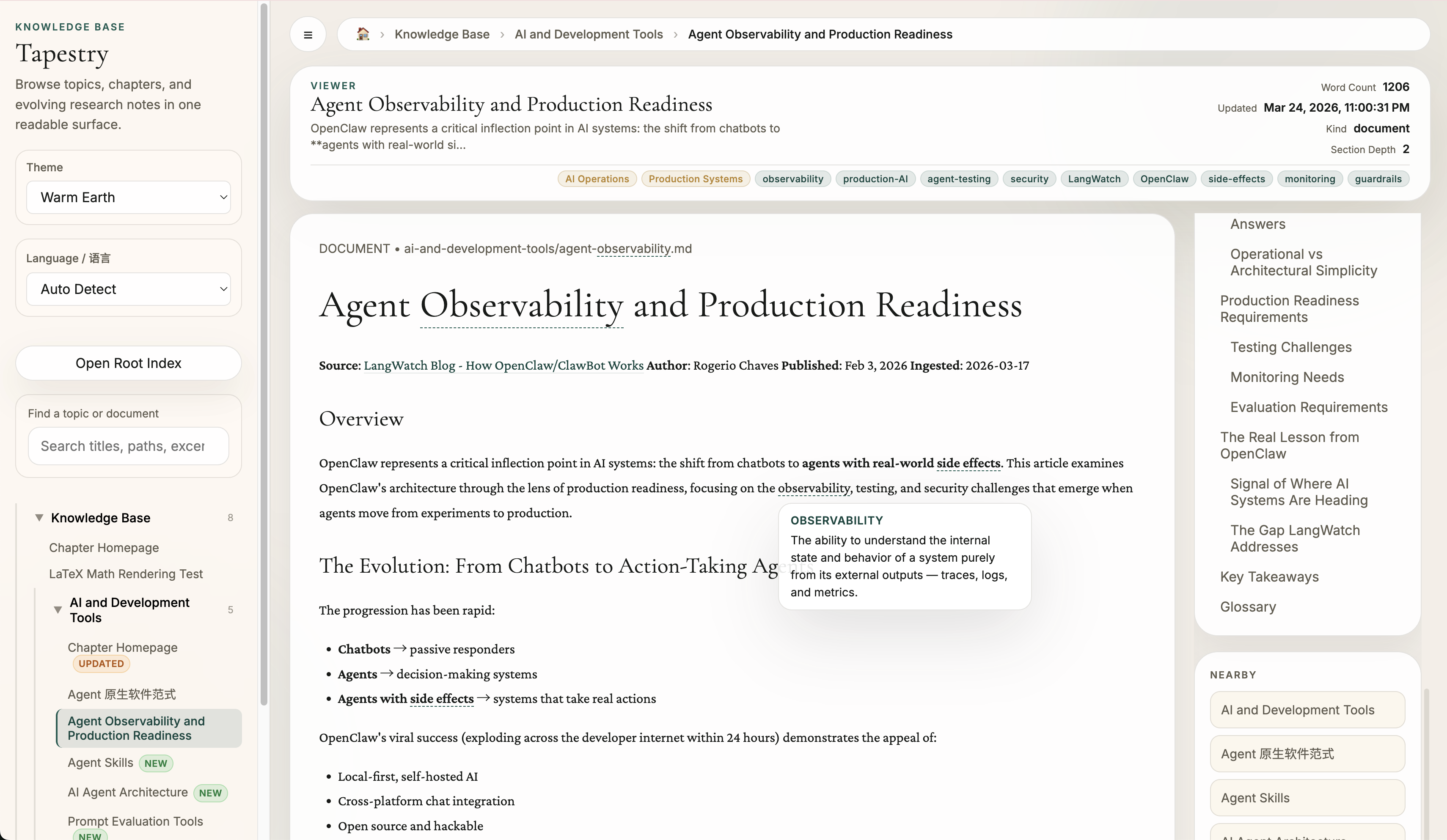

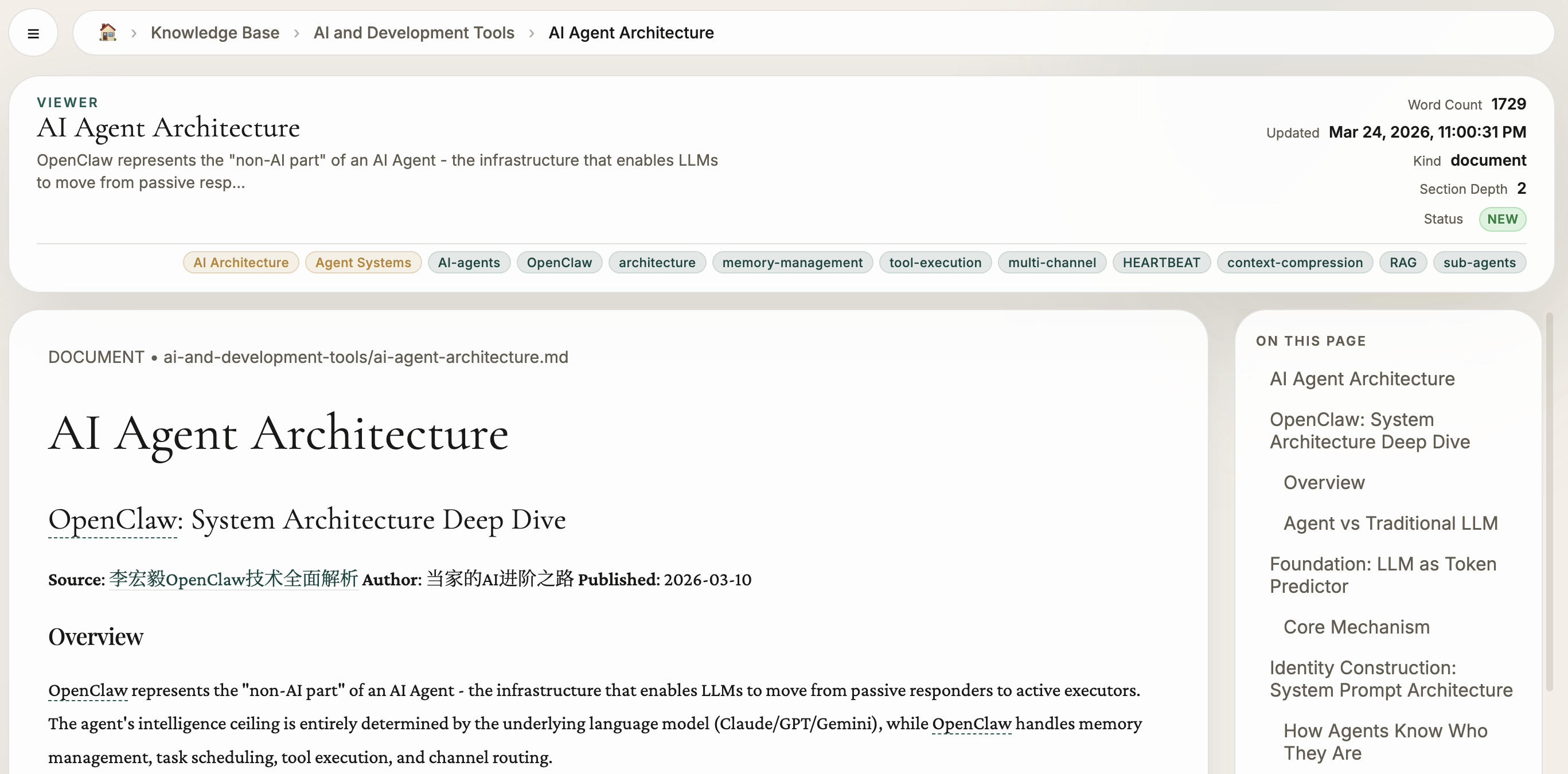
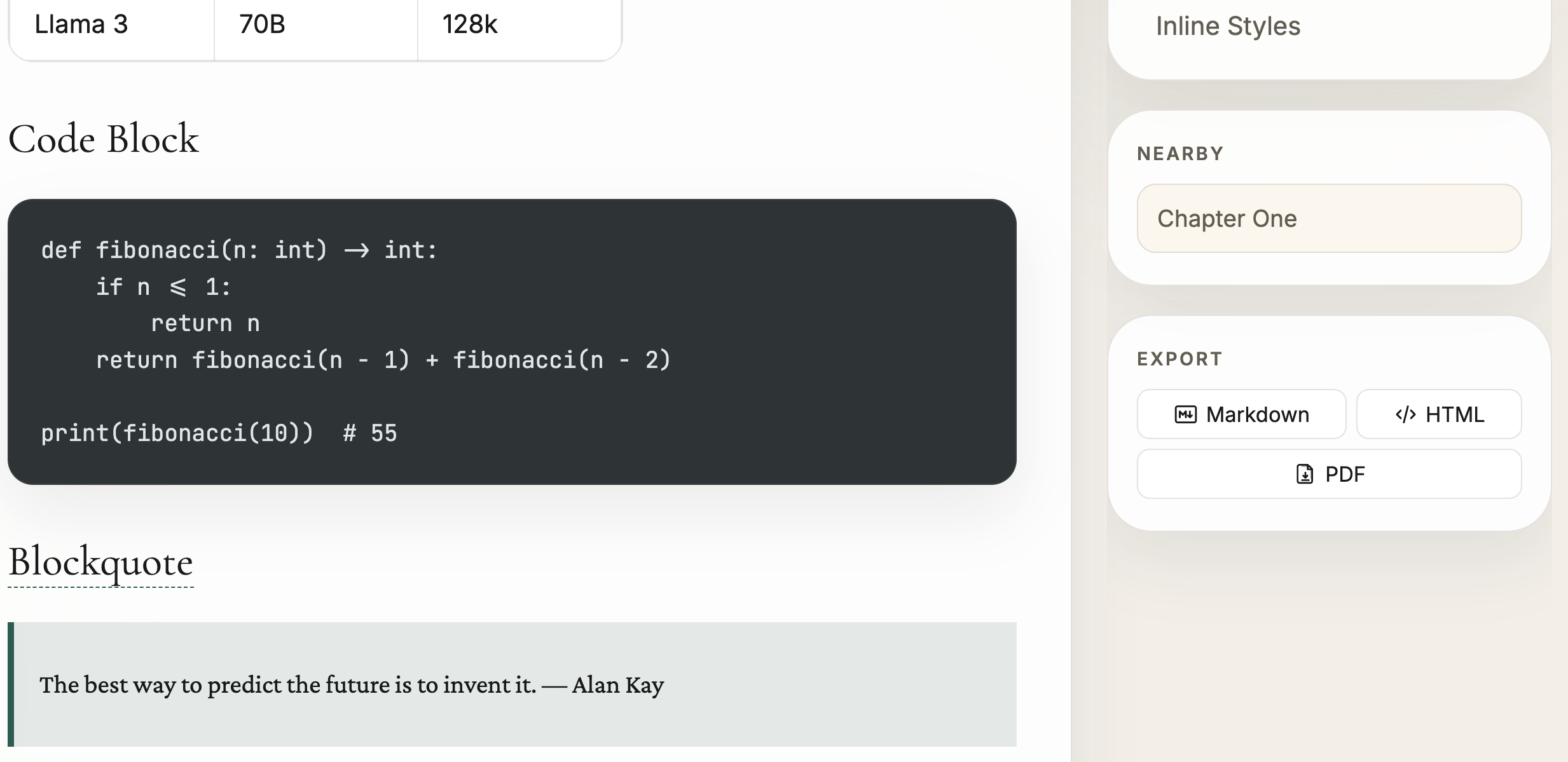
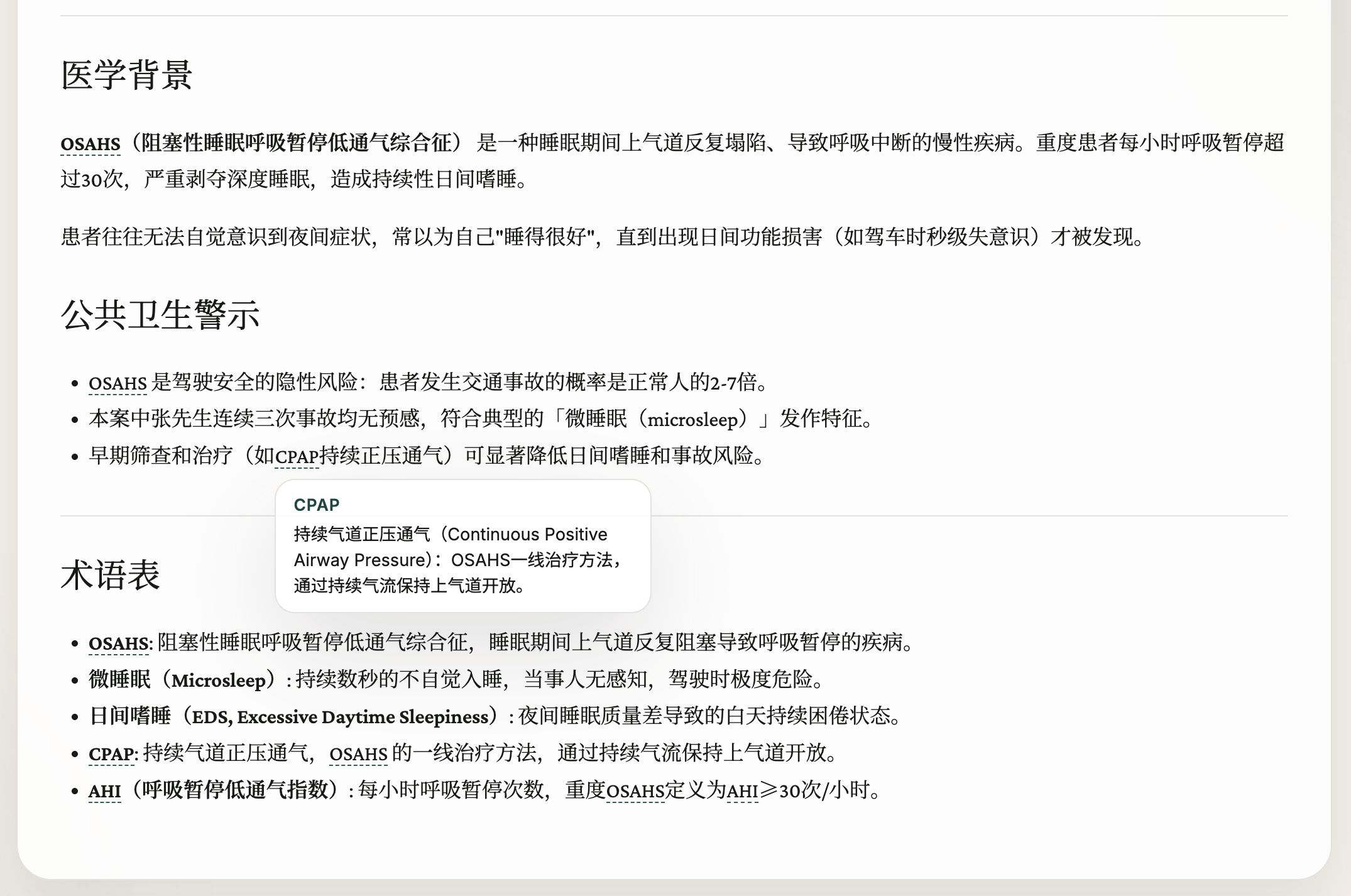
支持来源 · Knowledge Sources
Tapestry 提供来源感知的抓取范式,让异构内容进入统一的知识管线
Platform-aware crawlers, unified feed schema, and one knowledge model across every source type.
针对各个平台的专用 crawler,按来源类型路由,保留页面结构与上下文语义
无论来自知乎、微博还是通用 HTML,最终都归一化到可索引、可去重的标准化 Feed 层
异构来源被组织进同一套笔记、章节、目录与展示结果,而非散落的文件堆
知乎
Zhihu
覆盖问题、回答、专栏与评论链,适合沉淀中文知识社区中的长链路问答与观点结构
Reddit
Threaded communities
完整保留 thread 层级与评论树,为后续聚类、综合与引用关系提供结构基础
Hacker News
Technical link discussions
抓取技术链接、高信号评论串与开发者反馈,合并保存新闻入口与原始讨论
X / Twitter
Fast public signals
短帖、转发链与公共信号快照,捕捉长文来源之外的实时舆论与观点传播
微信公众号
WeChat articles
图文长文、栏目内容与公众号资料,连续发布的内容自动组织进统一主题与章节体系
微博
Weibo trends
热度追踪、短消息扩散与公开反应记录,保留舆论变化与时间线上下文
小红书
Xiaohongshu
图文笔记与视觉导向内容,视觉表达、生活方式语境与文本说明一起纳入知识库
通用 HTML
Generic HTML pages
覆盖普通网页与未定制站点的通用后备入口,来源扩展能力不受平台边界限制
延展页面 · Explore More
从安装、来源覆盖到实际工作流,Tapestry 的核心页面在这里进一步展开
Explore the public pages that explain how Tapestry installs, what it can capture, and how its workflow turns source material into durable knowledge assets.
安装指南 · Install
接入与安装方式
Bundle-first setup across Claude Code, Codex, OpenClaw, and manual release installs.
查看插件市场、npx skills 与手动 bundle 的接入方式,以及首轮验证应该怎么跑。
来源覆盖 · Sources
平台支持与 crawler 能力
Platform-aware coverage for Zhihu, Reddit, Hacker News, X, Xiaohongshu, Weibo, WeChat articles, and generic HTML.
了解 Tapestry 如何保留来源结构与上下文,再把异构内容整理进统一的知识管线。
使用场景 · Use Cases
真实工作流里的应用方式
Research monitoring, evidence archives, topic curation, and knowledge-base publishing.
查看哪些任务最适合用 Tapestry 来持续积累、综合与发布知识资产。
常见问题 · FAQ
快速了解项目边界
Straight answers about installation, storage roots, source-aware crawling, and publishing.
如果你想快速确认项目定位、数据去向和发布路径,这一页是最直接的入口。